



Originally published on Medium
Updated on 2020–12–26: After posting this, I realized that it could be improved this, even more, by using DynamoDB TTL. I updated this article accordingly.
While I was working on a GraphQL API, I needed a couple of resolvers hitting remote HTTP endpoints. This is rather straightforward with AppSync HTTP data sources. However, I didn't want it hitting the remote APIs at every single request. There were several reasons for that:
Latency: Due to several factors, like the location of the remote endpoint, it could add a noticeable overhead and add extra time to the request execution.
Throttling: I did not want to spam the remote endpoints and suffer possible throttling, or even worst: being banned.
API quotas: Some of the remote endpoints also had quotas and I did not want to reach the limits too fast.
Because most of the data was not going to change over time anyway, the natural choice, in this case, was to use a cache layer.
My first instinct was to turn towards the AppSync caching capabilities. AppSync comes out-of-the-box with a built-in server-side cache. It offers per-request and per-resolver caching. Unfortunately, it had two drawbacks for me:
Cost: Starting at $0.044 up to $6.775 per hour, it can quickly become expensive if the workload increases.
TTL is limited to 3600 seconds, after what cached data will expire.
The main issue for me here was the time limit. With a 1-hour cache TTL, data would be flushed every hour and the remote endpoints would have to be hit again. In my case, this was still too often, especially because I was totally OK with a day-old data or even a month-old, in some cases. So, I started looking for alternatives.
The data I had to store was plain JSON objects. So I thought: how about DynamoDB? I could store them as a document in a table. Then, I could have a resolver that looks into the table for a given cache key. If the record is found (and hasn't expired), return it; otherwise, fetch fresh data from the source, store it into the table for later and return the data. Because DynamoDB is fast, it sounded like a good idea.
Now, a naive approach would have been to use a Lambda resolver that would do just that. It would have worked for sure, but there is a better alternative that is faster and cheaper. AppSync supports pipeline resolvers. Pipeline resolvers let you execute multiple operations, or "functions", to resolve one single field. This was just what I needed. My resolver would be composed of 3 functions:
Try and fetch data from a DynamoDB table. If there is a hit, **skip the following functions **and return the data.
If there was no hit, go fetch the remote data from the source.
Save the data into the DynamoDB table and return it.
Let me show you how I implemented this with a simplified example. In this demo, we will build a GraphQL API that fetches Wikipedia articles. Because we don't want to spam Wikipedia's servers and because articles don't change that much very often, they should be cached for a month before we have to hit Wikipedia again and get the updated versions.
To build that, we will use the Serverless Framework and the AppSync plugin. I will not go into details on how the plugin works. For more information, please refer to the documentation on the repository or this series of articles.
I will explain the most important parts only, but you can find the full code of this example on GitHub.
Let's start with the serverless.yml.
mappingTemplates:
- type: Query
field: wikipedia
kind: PIPELINE
functions:
- fetchFromCache
- fetchWikipedia
- saveToCache
dataSources:
- type: HTTP
name: wikipedia
description: 'Wikipedia api'
config:
endpoint: https://en.wikipedia.org
- type: AMAZON_DYNAMODB
name: wikicache
description: 'Wikipedia cached titles'
config:
tableName:
Ref: WikipediaTable
functionConfigurations:
- dataSource: wikicache
name: fetchFromCache
- dataSource: wikicache
name: saveToCache
- dataSource: wikipedia
name: fetchWikipedia
resources:
Resources:
WikipediaTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: wikipedia
BillingMode: PAY_PER_REQUEST
TimeToLiveSpecification:
AttributeName: expires_at
Enabled: true
AttributeDefinitions:
- AttributeName: title
AttributeType: S
- AttributeName: expires_at
AttributeType: N
KeySchema:
- AttributeName: title
KeyType: HASH
mappingTemplates
This is where we define our resolver. As I explained earlier this is going to be a PIPELINE resolver with three consecutive functions: fetchFromCache, fetchWikipedia and saveToCache.
dataSources
Here we define our two data sources:
an HTTP endpoint which points to the Wikipedia API in English
a DynamoDB table
functionConfigurations
And here, we declare the 3 pipeline functions that we use in the data source we created earlier.
WikipediaTable resource
Finally, we declare our DynamoDB table. It will have a HASH key, which will be the title of the article. We also set a TimeToLiveSpecification on the expires_at attribute.
DynamoDB Time to Live (TTL) is a feature that allows us to define a per-record timestamp when the record is no longer needed. When the timestamp is reached, the record is deleted. We will use that in order to auto-expire the cache.
Now, we need to define our mapping templates. There are a few of them. Let's go through them in the order they will be executed.
Let's begin with the "before" pipeline request mapping template.
## Query.wikipedia.request.vtl
$util.qr($ctx.stash.put("title", $ctx.args.title))
{}
Here, we simply put the title argument coming from the request into the stash (see the schema definition). We will use it later in the pipeline. We also return an empty Map (because mapping templates cannot be empty).
At this point, the first function in the pipeline will be called: fetchFromCache
## fetchFromCache.request.vtl
{
"version": "2018-05-29",
"operation": "GetItem",
"key": {
"title": $util.dynamodb.toStringJson("${ctx.stash.title}")
}
}
Here, we execute a GetItem operation on our DynamoDB table using the title of the article as the key. Let's see what is in the response template:
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#if($ctx.result)
$util.qr($ctx.stash.put("result", $ctx.result.content))
#end
{}
First, check for any error, and stop the process if we find any. Then, if we have a result (it means that we have a hit!), we stick it into the stash. You will find out why later.
Now, at this point, if we have a hit, we want to stop the execution and return the value to the user. It turns out that AppSync has a neat solution for that: the return directive.
The
#returndirective comes handy if you need to return prematurely from any mapping template.#returnis analogous to the return keyword in programming languages, as it will return from the closest scoped block of logic. What this means is using#returninside a resolver mapping template will return from the resolver. Additionally, using#returnfrom a function mapping template will return from the function and will continue the execution to either the next function in the pipeline or the resolver response mapping template.
The important part to notice here is that, when used in a pipeline function, *#returnwill continue to the next function in the pipeline. But we don't want the next function to be executed, right? Well, it turns out that if you call *#return in a request mapping, it will skip to the next function without executing the current one.
This is why we previously kept the result into the stash. We will use it in the following two functions' request mappings to determine if there was a hit, and skip to the next one directly, in cascade. See our fetchWikipedia request template:
## fetchWikipedia.request.vtl
## Bypass this function if result is present in the stash
#if($ctx.stash.result)
#return($ctx.stash.result)
#end
{
"version": "2018-05-29",
"method": "GET",
"params": {
"query": {
"action": "query",
"format": "json",
"prop": "extracts",
"exintro": "true",
"titles": "${ctx.stash.title}",
"explaintext": "true",
"exsentences": 10
}
},
"resourcePath": "/w/api.php"
}
If we have a result in the stash, we call *#return* prematurely and continue to the next function. Otherwise, the function would get executed, the API endpoint would be called and the response template too, where we extract the data we need. Here it is:
## fetchWikipedia.response.vtl
#if($ctx.result.statusCode == 200)
#set($body = $utils.parseJson($ctx.result.body))
#foreach ($page in $body.query.pages.entrySet())
#if ($page.value.title == $ctx.args.title)
#return($page.value.extract)
#end
#end
$utils.error("Article not found", "NotFound")
#else
$utils.error($ctx.result.statusCode, "Error")
#end
All right, we are almost there. There is just one last function to define.
Remember, if we return early within any function, the return directive will skip to the next function. So, here again, we need to check if we have a result in the stash and return early one more time. Otherwise, this is where we save the result from the previous function into DynamoDB. We also set an expiry timestamp for 30 days in the future:
## saveToCache.request.vtl
## Bypass this function if result is present in the stash
#if($ctx.stash.result)
#return($ctx.stash.result)
#end
#set($expires_at = $util.time.nowEpochSeconds() + 3600 * 24 * 30)
{
"version" : "2018-05-29",
"operation" : "PutItem",
"key" : {
"title" : $util.dynamodb.toStringJson(${ctx.stash.title})
},
"attributeValues": {
"expires_at": $util.dynamodb.toNumberJson($expires_at),
"content": $util.dynamodb.toStringJson($ctx.prev.result)
}
}
And we return the result.
## saveToCache.response.vtl
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$utils.toJson($ctx.prev.result)
Finally, our "after" pipeline just forwards the result to the resolver
## Query.wikipedia.response.vtl
$util.toJson($ctx.result)
And we are done!
Let's deploy, run some queries and look at the X-Ray traces to confirm what we just built works as expected.
We will use the following query and execute it, twice:
query {
wikipedia(title: "Cat")
}
which generates the following traces.
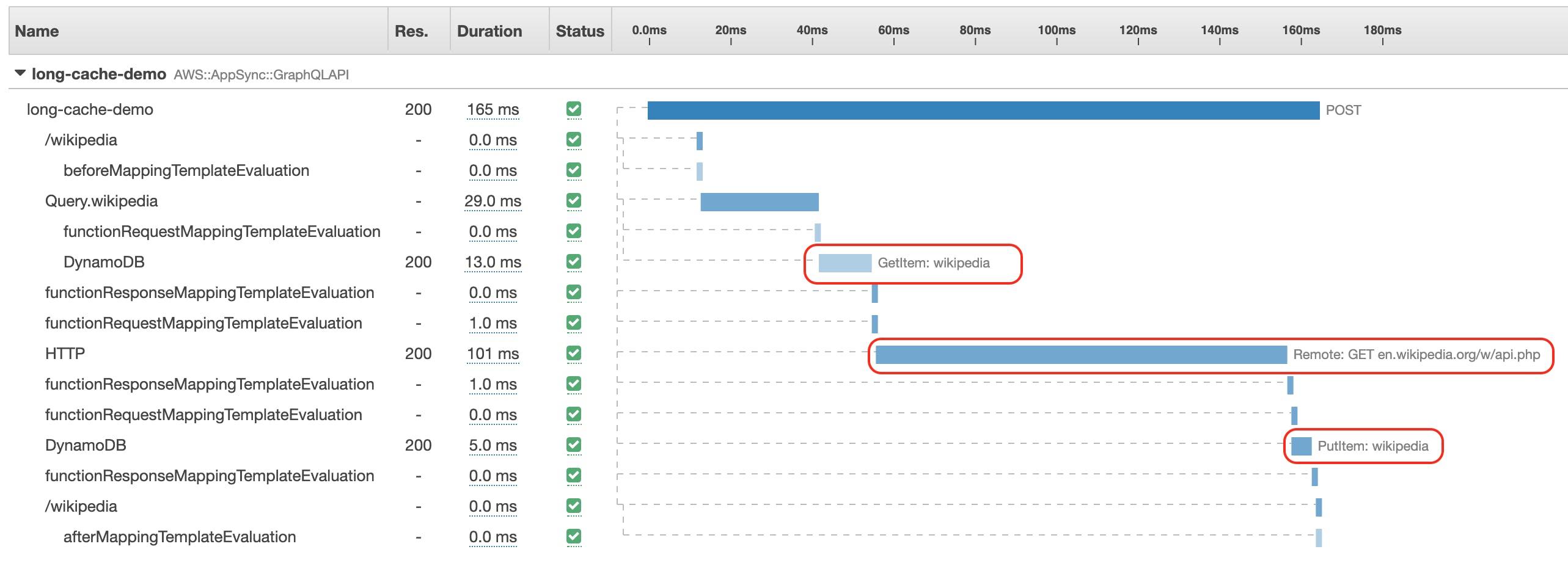
Traces of the first execution
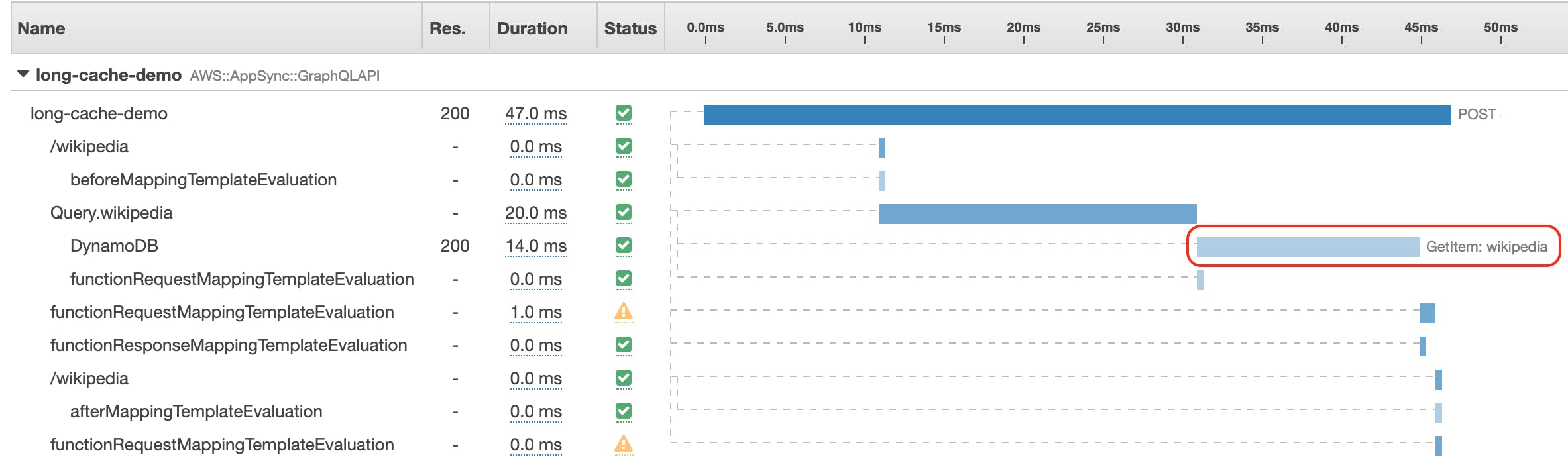
Traces of the second execution
As you can see, the first time, our resolver executed the three steps sequentially. The second time though, only the GetItem operation was executed. The HTTP request was not executed at all and our resolver execution time even went down from 165ms to 47ms. Isn't that nice?
If you look carefully you will also notice 2 warning signs. These are the request mapping templates where we do an early return. I am not sure why X-Ray shows that as warnings but there are no errors at all showing in the details or the CloudWatch logs, and everything works as expected.
Here you have it, a long-term cache layer for AppSync, using only out-of-the-box functionalities.