

How to Handle Many to Many relations in AppSync
Learn How To Avoid Denormalization and Reduce the Number of DynamoDB Requests


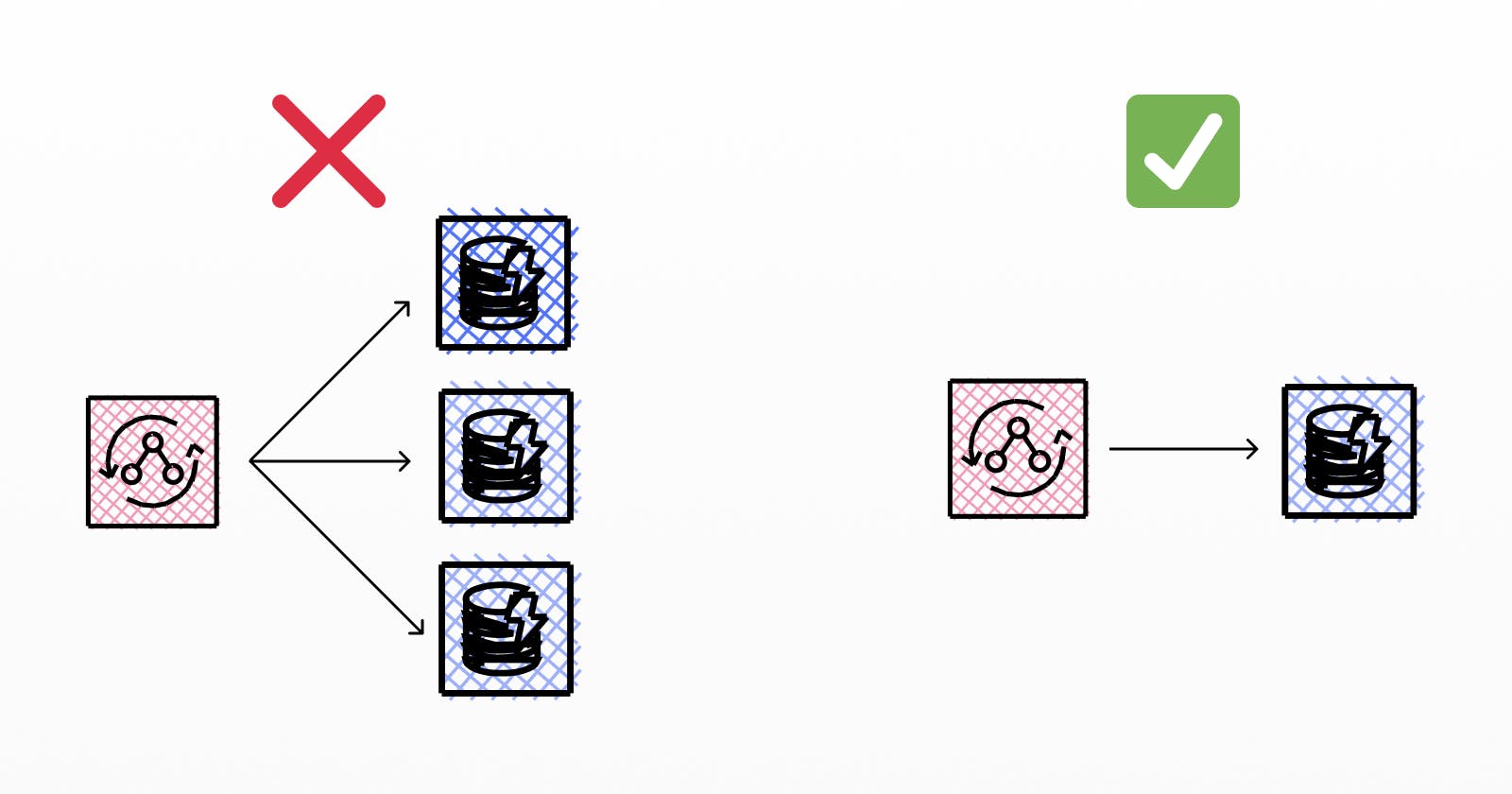
In this post, I will teach you how you can handle many-to-many relations with AWS AppSync, how to avoid denormalization and still avoid the n+1 problem.
TL;DR; Use a Pipeline resolver to first fetch the relations followed by a BatchGetItem operation to retrieve all related items in one single query.
Find the full solution on GitHub
The problem
One of the most common problems developers face when designing DynamoDB databases is many-to-many relationships. Usually, the recommended way is to denormalize your data. You duplicate all the fields required by your access pattern in the relation Item so that they are returned along with it. It avoids doing extra queries to the related items, as NoSQL databases can't operate JOIN operations.
Let's take an example. Imagine you are building an application that has users and groups. Users can be in several groups and groups may have multiple users.
Your data model might look like this:
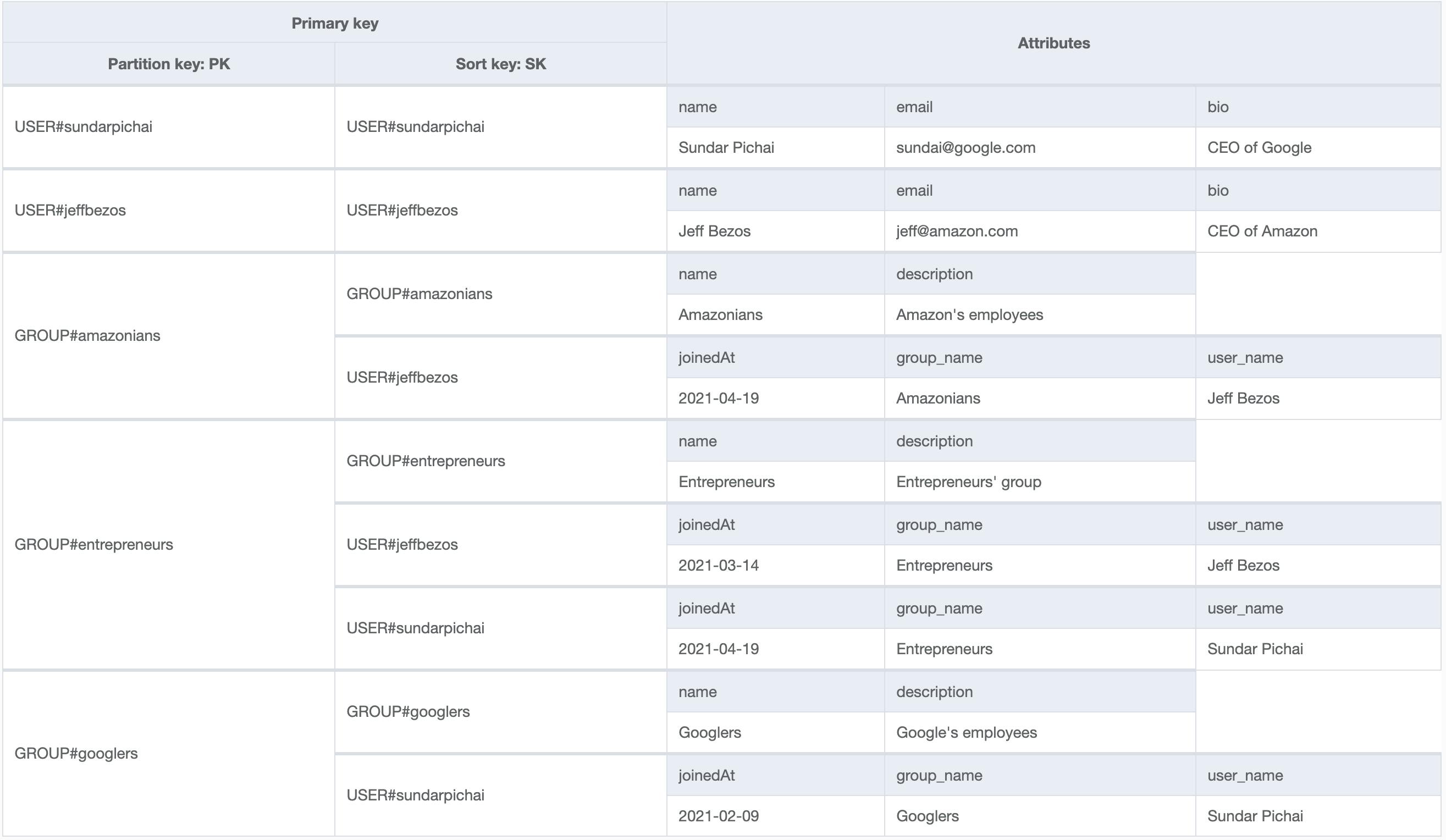
There are 2 problems with this design with GraphQL APIs:
1) The client might ask for fields that are not denormalized in the relation.
Since GraphQL is agnostic of the underlying data source and the types defined in the schema have all the fields defined (not just those that are denormalized), a query might request them. In our example, it might be the user's bio or profile picture. If these fields are not be denormalized in be the relation, they would be missing in the GraphQL response.
query {
getGroupUsers(id: ID!) {
id
name
# bio and picture are not denormalized in the relation
bio
picture
}
}
One approach to fix this would be to create a different type which is a subset of User. However, this defeats the purpose of GraphQL and might also not be what you want.
2) It is hard to keep the data up to date when it changes.
What if the user changes his username (think Twitter)? You will have to go through all the relation Items and update them. If the number of items is small, it can be manageable, but imagine a group that has thousands or millions of users! This can become a hassle to maintain and data can easily become out of sync.
Also, as explained before, with GraphQL in mind, you might end up having to denormalize the whole user item. This would not be a viable solution.
Resolvers to the rescue
One of the characteristics of GraphQL is resolvers. Resolvers are used to resolve child entities using data from the previously resolved ones (the source in AppSync).
One of the common approaches to solve the above problems would be to use a different resolver for the child entity (in our case: user). The implementation is pretty straightforward: first, resolve the relations, and then use them to resolve the underlying users (using the user id they contain).
For that to work, you would need to nest the user entity under the relation entity. This might not be a bad thing anyway, because you might want to return some metadata related to the relationship as well, such as a joinedAt attribute.
Example:
query {
getGroupUsers(id: ID!) {
joinedAt
user {
id
name
bio
picture
}
}
}
user is attached to a resolver that receives the user id from the group-user relation.
There is one problem with this approach though: It introduces an n+1 problem. ie: every child entity will trigger one extra query to DynamoDB each. If a group has 10 users, you will end up executing 11 queries (one for all the relations and 10 for each individual user)
A better approach: Pipeline & Batch resolvers
Pipelines allow you to compose a resolver out of different steps or functions. If you are not familiar with pipelines yet, I suggest you read the documentation
AppSync also supports DynamoDB Batch resolvers which you can use to act on several items in one single DynamoDB round-trip. There are three supported operations: BatchGetItem, BatchPutItem , and BatchDeleteItem.
The one we are interested in here is BatchGetItem. It can be used in order to retrieve up to 100 DynamoDB items in one single DynamoDB request.
With all these elements in hand, we can implement a pipeline resolver with two functions:
fetch the group-user relation items
fetch all the underlying user entities in one single query
Let's see how that works and build the getGroupUser endpoint.
The full solution is available on GitHub
In the getGroupUsers function (the first function of the pipeline), we first fetch the relation items between the group and the users. We also make sure not to go over the limit of 100 items imposed by BatchGetItem. After that, we'll need to paginate (more on that later).
## getGroupUsers - request mapping
#set($limit=$util.defaultIfNull($ctx.args.limit, 10))
#if($limit>100)
#set($limit=100)
#end
{
"version": "2018-05-29",
"operation": "Query",
"limit": $util.toJson($limit),
"nextToken": $util.toJson($ctx.args.nextToken),
"query" : {
"expression": "#PK = :PK and begins_with(#SK, :SK)",
"expressionNames" : {
"#PK": "PK",
"#SK": "SK"
},
"expressionValues" : {
":PK": $util.dynamodb.toStringJson("GROUP#${ctx.args.id}"),
":SK": $util.dynamodb.toStringJson("USER#")
}
}
}
The response mapping just forwards the items to the next function. We also keep nextToken into the stash in order to return it later to the client for pagination.
## getGroupUsers - response mapping
$util.qr($ctx.stash.put("nextToken", $ctx.result.nextToken))
$util.toJson($ctx.result.items)
The getBatchUsers function is where the magic happens. We build the Primary Key pairs (PK and SK) of our user items and pass them to the GetBatchItem query.
Before that, if the previous request returned no result, we just return an empty array straightway (bypassing thereby the extra query to DynamoDB).
## getBatchUsers - request mapping
#if($ctx.prev.result.size() == 0)
#return([])
#end
#set($keys=[])
#foreach($item in $ctx.prev.result)
## the user and PK/SK is the SK from the Item received from the previous function
$util.qr($keys.add({
"PK": $util.dynamodb.toDynamoDB(${item.SK}),
"SK": $util.dynamodb.toDynamoDB(${item.SK})
}))
#end
{
"version": "2018-05-29",
"operation": "BatchGetItem",
"tables" : {
## replace this with your table's name
"table-name": {
"keys": $util.toJson($keys)
}
}
}
Once we get to our response mapping, we have to restructure our data a bit and inject the user entities into the relation items returned by the previous pipeline function.
## getBatchUsers - response mapping
#set($items=[])
#foreach($item in $ctx.result.data.get("table-name"))
#set($groupUser=$ctx.prev.result.get($foreach.index))
$util.qr($groupUser.put("user", $item))
$util.qr($items.add($groupUser))
#end
$util.toJson($items)
Finally, in our after mapping, we return the data we previously aggregated and we also send the nextToken back to the client to allow for pagination.
## getUsers - after mapping
$util.toJson({
"nextToken": $ctx.stash.nextToken,
"items": $ctx.result
})
Here you have it! Now, no matter how many user entities the group has, you would only be sending 2 requests to DynamoDB!
💡 Did you know?
In DynamoDB,
BatchGetItemdoes not guarantee to return the items in any particular order. However, AppSync does the heavy lifting for you and returns them in the same order as the keys. You, therefore, don't need to worry about it. 🙌
There is one important thing to notice, though:
BatchGetItem will have zero impact on your AWS bill. Fetching 100 items in batch will consume exactly the same RCUs as doing 100 individual GetItem requests. The only difference is that it can reduce the HTTP overhead and slightly improve latency.
Conclusion
In this post, we learned how to reduce the number of DynamoDB requests in many-to-many relationships with AppSync using pipeline resolvers and fetching items in batch from DynamoDB.
If you are interested in AppSync, I regularly share content related to it on Twitter and on this blog, so make sure to follow me and subscribe to my newsletter.
If you have any question, feel free to drop them in the comment section, and if you would like to receive advice or coaching from me about AppSync or Serverless, you can book a 1:1 conference or chat with me